1. 로지스틱 회귀분석
로지스틱 회귀(Logistic Regression)는 주로 이진 분류(binary classification) 문제를 다루는 머신러닝 알고리즘 중 하나입니다. 이 알고리즘은 선형 회귀(Linear Regression)와 달리 종속 변수가 이항 분포(binomial distribution)를 따르며, 결과값이 0 또는 1인 경우에 사용됩니다. 예를 들어, 고객이 제품을 구매할지 여부, 메일이 스팸인지 아닌지, 환자가 양성 종양을 가지고 있는지 여부 등을 예측하는 데 활용됩니다.
2. 파이썬 코드 예제
1) 데이터 불러오기
# 필요한 라이브러리 임포트
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix
# breast_cancer 데이터셋 로드
data = load_breast_cancer()
X = data.data
y = data.target
breast_cancer 데이터셋은 유방암 진단에 관련된 특성을 담고 있는 데이터셋입니다. 이 데이터셋은 유방암 세포의 특징을 기반으로 악성(malignant)과 양성(benign) 종양을 분류하는 문제를 다룹니다. 해당 데이터셋은 미국 위스콘신 대학의 Dr. William H. Wolberg가 수집한 Fine Needle Aspirate(FNA) 검사 결과를 기반으로 만들어졌습니다.
- 반지름(Radius): 세포 핵의 평균 반지름.
- 질감(Texture): 회색조 값의 표준편차.
- 둘레(Perimeter): 세포 핵의 둘레 길이.
- 면적(Area): 세포 핵의 면적.
- 비율(Compactness): 둘레^2 / (면적 - 1.0).
- 곱셈(Mean concavity): 세포 핵의 평균 오목함.
- 오목점(Mean concave points): 세포 핵의 평균 오목한 지점의 수.
- 대칭(Symmetry): 대칭성.
- 프랙탈 차원(Fractal dimension): 프랙탈 차원.
각 특성은 평균(mean), 표준오차(standard error), 최대값(worst)의 세 가지 측정값으로 제공됩니다. 이 데이터셋은 569개의 샘플로 이루어져 있습니다.
2) 학습용(training)과 테스트용(test)으로 나누기
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
이 과정은 모델을 훈련시키고 나서 모델의 성능을 평가하기 위해 데이터를 분리하는 데 사용됩니다. train_test_split 함수는 데이터를 80%의 학습 데이터와 20%의 테스트 데이터로 분할합니다. 이렇게 나누어진 데이터는 각각 X_train, X_test, y_train, y_test에 저장되며, 이를 활용하여 모델을 훈련하고 평가합니다. 데이터셋이 상대적으로 작을 때 7:3의 비율을 사용하고 일반적으로 8:2의 비율을 사용합니다. random_state는 데이터를 무작위로 섞거나 분할할 때 사용되는 난수 발생기의 시드(seed) 값입니다. 난수 발생기는 초기 시드 값을 기반으로 난수를 생성하며, 동일한 시드 값을 사용하면 항상 동일한 난수가 생성됩니다.
3) 모델 만들기
# 로지스틱 회귀 모델 생성 및 학습
model = LogisticRegression()
model.fit(X_train, y_train)
# 테스트 데이터 예측
y_pred = model.predict(X_test)
# 정확도 및 혼동 행렬 출력
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
print(f'Accuracy: {accuracy}')
print('Confusion Matrix:')
print(conf_matrix)Accuracy: 0.9649122807017544
Confusion Matrix:
[[40 3]
[ 1 70]]- 정확도가 약 0.96으로 굉장히 높게 나왔습니다. 정확도는 전체 예측 중 올바르게 예측한 비율을 나타냅니다. 정확도는 다음과 같이 계산됩니다: Accuracy=올바른 예측 수전체 예측 수 ÷
혼동 행렬은 모델의 성능을 더 세부적으로 평가하기 위한 표입니다. 이는 각 클래스에 대해 모델이 얼마나 맞추었는지, 틀렸는지를 나타냅니다. 혼동 행렬은 예측값과 실제값을 기반으로 다음과 같이 구성됩니다.
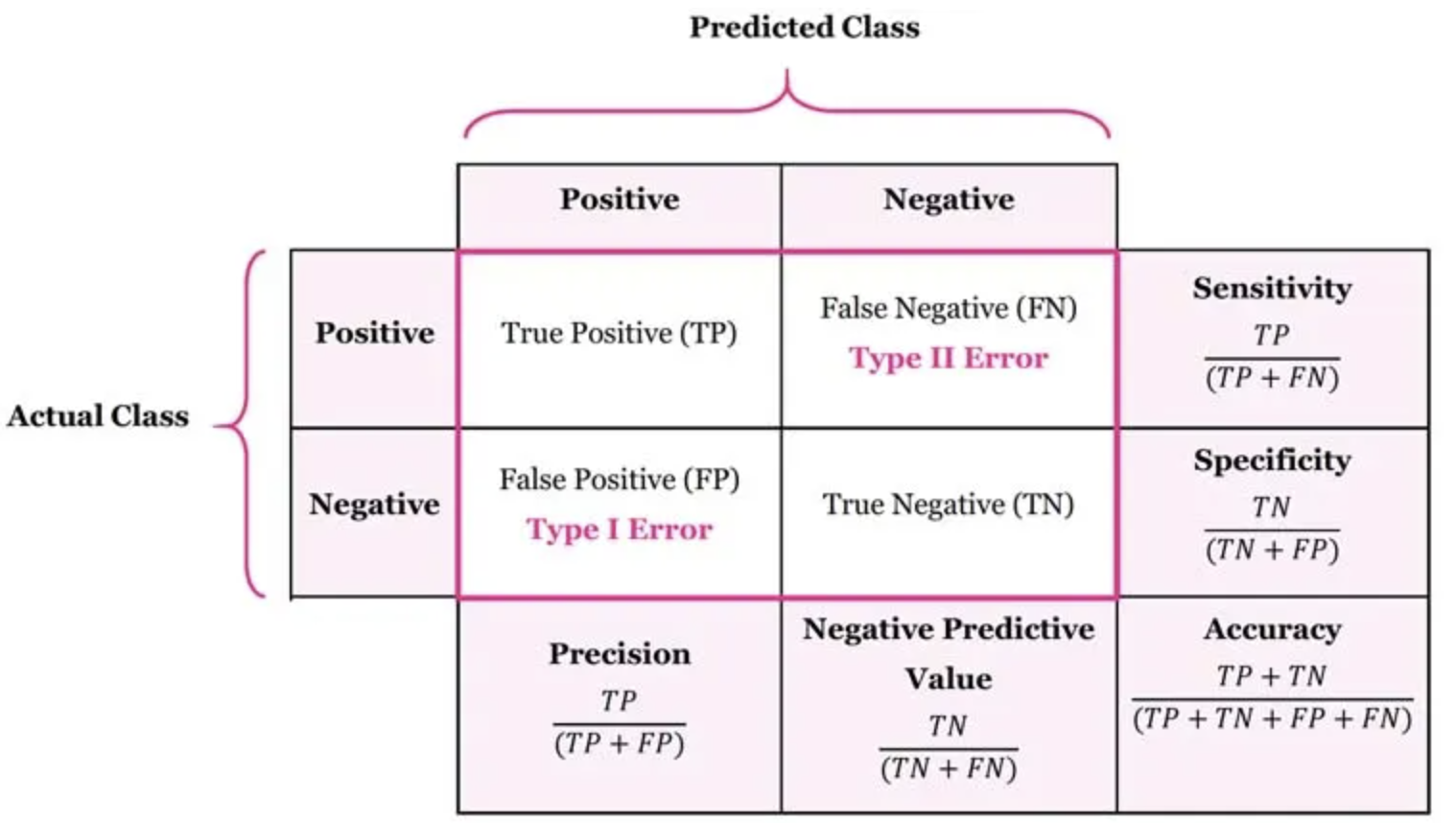
- True Negative (TN )
- 실제 값이 Negative이고 모델이 Negative로 예측한 경우입니다.
- 예를 들어, 실제로 건강한 사람을 건강한 것으로 정확하게 예측한 경우입니다.
- False Positive (FP )
- 실제 값이 Negative이지만 모델이 Positive로 잘못 예측한 경우입니다.
- 예를 들어, 실제로 건강한 사람을 질병이 있는 것으로 잘못 예측한 경우입니다.
- False Negative (FN)
- 실제 값이 Positive이지만 모델이 Negative로 잘못 예측한 경우입니다.
- 예를 들어, 실제로 질병이 있는 사람을 건강한 것으로 잘못 예측한 경우입니다.
- True Positive (TP)
- 실제 값이 Positive이고 모델이 Positive로 정확하게 예측한 경우입니다.
- 예를 들어, 실제로 질병이 있는 사람을 정확하게 질병이 있는 것으로 예측한 경우입니다.
5) 회귀 계수 그래프
# 회귀계수 그래프
plt.figure(figsize=(12, 6))
plt.bar(range(len(model.coef_[0])), model.coef_[0], color='green', alpha=0.7)
plt.title('Logistic Regression Coefficients')
plt.xlabel('Feature Index')
plt.ylabel('Coefficient Value')
plt.show()

로지스틱 회귀 모델에서 각 특성(feature)의 회귀 계수(coefficients)를 시각화한 것입니다. 로지스틱 회귀에서는 각 특성의 가중치를 나타내는 회귀 계수가 있으며, 이 값은 해당 특성이 모델의 예측에 얼마나 영향을 미치는지를 나타냅니다.
여기서 하나 고민할 문제가 있습니다. 모든 변수를 사용할 경우 다중공선성 문제로 인해 제대로 된 문제를 만들 수 없게 됩니다.다중공선성(multicollinearity)은 회귀 분석에서 독립 변수들 간에 강한 선형 의존성이 있는 경우 발생하는 문제를 나타냅니다. 즉, 하나의 독립 변수가 다른 독립 변수들의 조합으로 잘 예측될 수 있는 상황을 의미합니다. 아래는 상관계수가 낮은 변수만을 활용하여 동일한 분석을 진행한 코드 예시입니다.
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix
# breast_cancer 데이터셋 로드
data = load_breast_cancer()
X = data.data
y = data.target
# 데이터프레임 생성
df = pd.DataFrame(X, columns=data.feature_names)
df['target'] = y
# 상관 계수가 일정 임계값 이하인 변수 선택
threshold = 0.3 # 임계값 설정 (상관 계수의 절대값이 이 값 이하인 변수 선택)
corr_matrix = df.corr().abs()
lower_tri = corr_matrix.where(np.tril(np.ones(corr_matrix.shape), k=-1).astype(np.bool))
to_drop = [column for column in lower_tri.columns if any(lower_tri[column] < threshold)]
# 상관 계수가 일정 임계값 이하인 변수만 선택
X_selected = df.drop(columns=to_drop)
y_selected = df['target']
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X_selected, y_selected, test_size=0.2, random_state=42)
# 로지스틱 회귀 모델 생성 및 학습
model = LogisticRegression()
model.fit(X_train, y_train)
# 테스트 데이터 예측
y_pred = model.predict(X_test)
# 정확도 및 혼동 행렬 출력
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
print(f'Accuracy: {accuracy}')
print('Confusion Matrix:')
print(conf_matrix)Accuracy: 1.0
Confusion Matrix:
[[43 0]
[ 0 71]]
'Python, R 분석과 프로그래밍 > 머신러닝' 카테고리의 다른 글
| 머신러닝 - 보스턴 하우징 데이터 (0) | 2023.08.15 |
|---|---|
| 머신 러닝 - 타이타닉 생존자 분석 (0) | 2023.08.13 |