Gapminder 데이터셋은 세계 각 국가에 대한 시간에 따른 다양한 경제 지표 및 사회 지표를 수집한 데이터입니다. 이 데이터셋은 Gapminder Foundation에서 수집하고 제공하며, 세계의 국가들에 대한 주요 지표들의 시계열 데이터를 담고 있습니다. Gapminder 데이터셋에 포함된 주요 변수들로는 국내총생산(Gross Domestic Product, GDP), 인구, 기대수명, 출생률, 사망률, 대륙 등이 있습니다. 이 데이터셋은 연도별로 국가들의 상황을 기록하고 있어, 다양한 시각화 및 데이터 분석에 활용됩니다.
(1) 데이터 불러오기
# 라이브러리 불러오기
import pandas as pd
from gapminder import gapminder
# 데이터 불러오기
data = gapminder.copy()
# 데이터 크기 확인
data.shape
[결과값]
(1704, 6)
(2) 데이터 살펴보기
#데이터 정보 요약
data.info()
[결과값]
전체 행의 수는 1704이고, 총 6개의 열을 가지고 있습니다. 데이터 타입은 문자열(object), 정수(int64), 실수(float64)로 구성되어 있고 누락된 값은 없습니다.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1704 entries, 0 to 1703
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 country 1704 non-null object
1 continent 1704 non-null object
2 year 1704 non-null int64
3 lifeExp 1704 non-null float64
4 pop 1704 non-null int64
5 gdpPercap 1704 non-null float64
dtypes: float64(2), int64(2), object(2)
memory usage: 80.0+ KB
(3) 여러가지 그래프를 그려보자
# 미국의 GDP 시계열 데이터
usa_data = data[data['country'] == 'United States']
plt.figure(figsize=(12, 6))
plt.plot(usa_data['year'], usa_data['gdpPercap'], marker='o')
plt.title('GDP per Capita Over Time (United States)')
plt.xlabel('Year')
plt.ylabel('GDP per Capita')
plt.show()
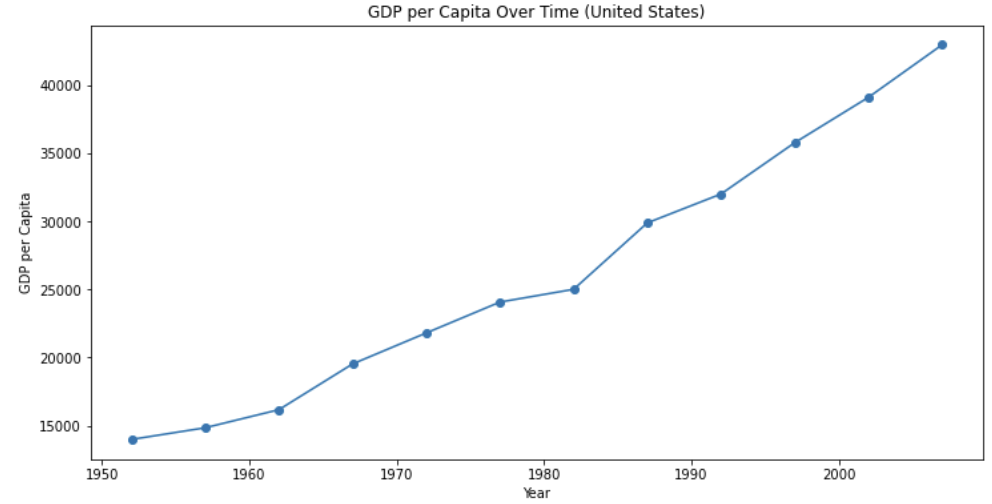
이 그래프를 통해 미국의 GDP per Capita가 연도에 따라 어떻게 변화했는지를 시각적으로 확인할 수 있습니다. 경제 성장이나 감소, 특정 시기의 변동성 등을 파악할 수 있습니다.
- X 축 (Year): 그래프의 x 축은 연도를 나타냅니다. 1952년부터 2007년까지의 미국의 GDP per Capita 변화를 보여줍니다.
- Y 축 (GDP per Capita): 그래프의 y 축은 GDP per Capita를 나타냅니다. 이 값은 해당 연도의 미국의 GDP를 인구 수로 나눈 값으로, 1인 당 평균 GDP를 의미합니다.
- 그래프의 형태: 그래프는 각 연도별로 미국의 GDP per Capita를 나타내는 점(line plot)으로 표현되어 있습니다. 각 점은 해당 연도의 GDP per Capita를 나타냅니다.
- Marker='o': 각 데이터 포인트는 동그라미(o)로 표시되어 있습니다.
- 그래프 제목: "GDP per Capita Over Time (United States)"라는 제목을 추가하였습니다.
- X 축 레이블 (Year): X 축에는 "Year"라는 레이블이 붙어 있어, X 축이 연도를 나타내는 것을 알려줍니다.
- Y 축 레이블 (GDP per Capita): Y 축에는 "GDP per Capita"라는 레이블이 붙어 있어, Y 축이 GDP per Capita를 나타내는 것을 알려줍니다.
# Top 10국가의 1인당 GDP 시각화
plt.figure(figsize=(14, 8))
sns.barplot(x='gdpPercap', y='country', data=top_gdp_countries, palette='viridis')
plt.title('Top 10 Countries by GDP per Capita (2007)')
plt.xlabel('GDP per Capita')
plt.ylabel('Country')
plt.show()
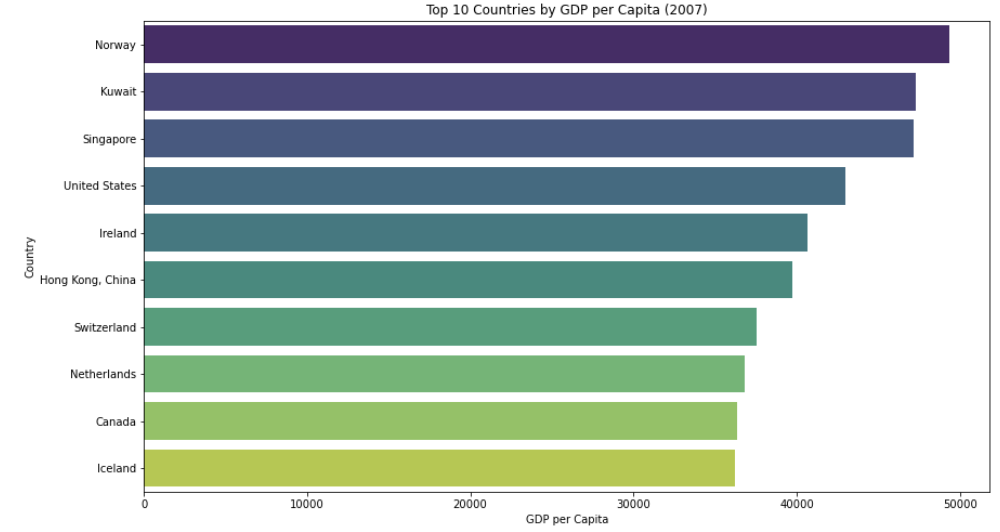
위 코드는 2007년 기준으로 상위 10개 국가의 1인당 GDP를 막대 그래프로 시각화하여 1인당 GDP가 높은 국가들을 한 눈에 볼 수 있는 장점이 있습니다.
#기대수명 vs. 1인당 GDP 산점도 그래프
plt.figure(figsize=(12, 8))
sns.scatterplot(x='gdpPercap', y='lifeExp', data=data_2007, hue='continent', palette='Set2', size='pop', sizes=(20, 2000))
plt.title('Life Expectancy vs. GDP per Capita (2007)')
plt.xlabel('GDP per Capita')
plt.ylabel('Life Expectancy')
plt.legend(title='Continent', loc='upper left')
plt.show()
- plt.figure(figsize=(12, 8)): 새로운 그림(figure)을 생성하고, 그림의 크기를 설정합니다. 이 경우에는 가로 12인치, 세로 8인치의 크기로 설정했습니다.
- sns.scatterplot(x='gdpPercap', y='lifeExp', data=data_2007, hue='continent', palette='Set2', size='pop', sizes=(20, 2000)): seaborn 라이브러리의 scatterplot 함수를 사용하여 산점도 그래프를 생성합니다.
- x='gdpPercap': x 축에는 1인당 GDP를 사용합니다.
- y='lifeExp': y 축에는 기대수명을 사용합니다.
- data=data_2007: 그래프에 사용할 데이터는 2007년의 데이터로 한정됩니다.
- hue='continent': 대륙별로 데이터를 구분하여 다른 색상으로 표시합니다.
- palette='Set2': 그래프에 사용할 색상 팔레트를 'Set2'로 지정합니다.
- size='pop': 각 점의 크기는 해당 국가의 인구 크기로 나타냅니다.
- sizes=(20, 2000): 인구 크기에 따라 표시되는 점의 크기 범위를 설정합니다.
- plt.legend(title='Continent', loc='upper left'): 대륙별로 다른 색상으로 표시된 점들에 대한 범례(legend)를 설정합니다. 범례의 위치는 왼쪽 상단으로 설정되어 있습니다.
- plt.show(): 그래프를 표시합니다.
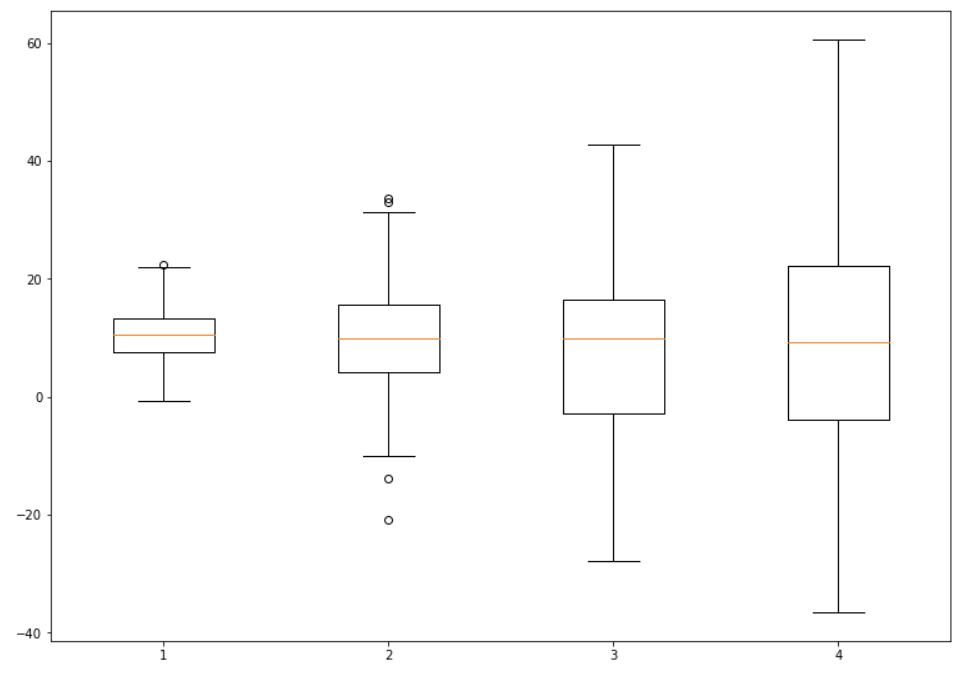
# 상자 그림 (Box Plot) - 대륙 별 기대수명 (2007)
sns.boxplot(data=data[data['year'] == 2007], x='continent', y='lifeExp', palette='Set2')
plt.title('Box Plot - Life Expectancy by Continent (2007)')
plt.show()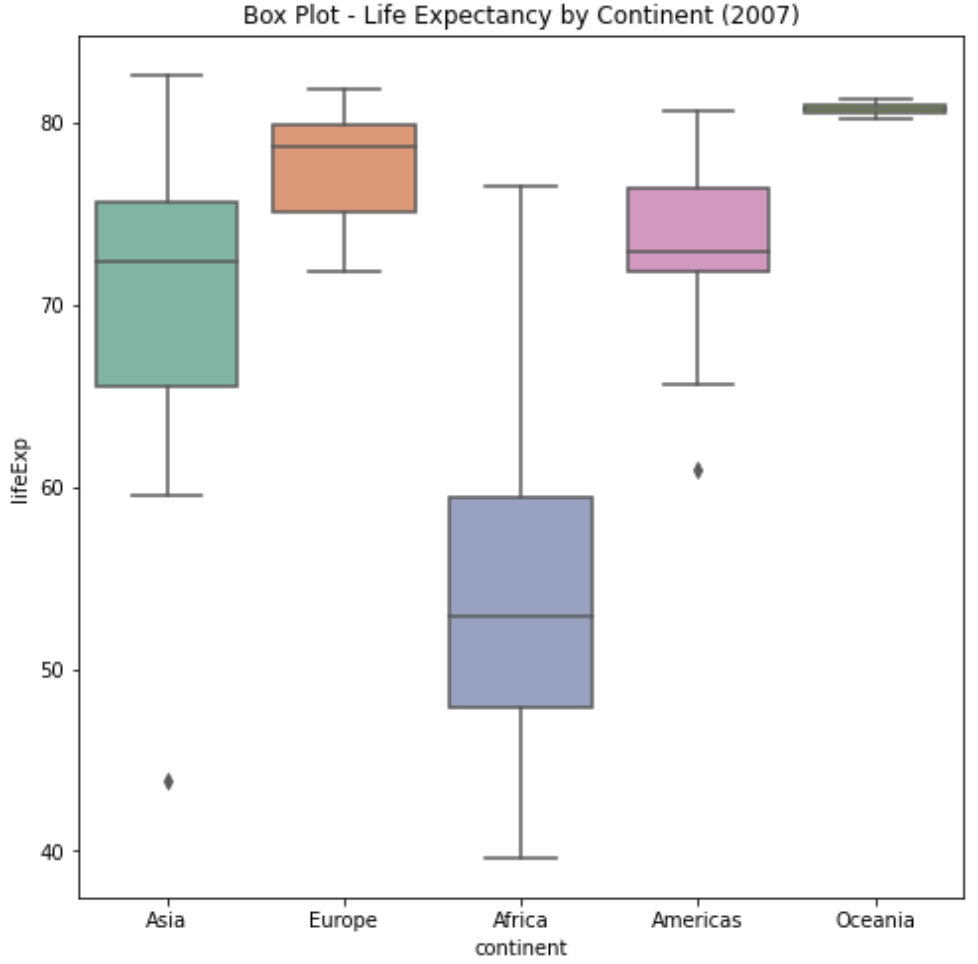
위 코드는 2007년 기준으로 대륙별 기대수명에 대한 상자 그림(Box Plot)을 생성하는 코드입니다. 이 그래프를 통해 대륙별로 기대수명의 분포를 시각적으로 확인할 수 있습니다. 각 대륙의 중앙값, 사분위수, 이상치 등이 상자 그림으로 표현되어 있습니다.
'Python, R 분석과 프로그래밍 > 데이터 시각화' 카테고리의 다른 글
| [python] 버블차트 그리기 (2) | 2024.01.05 |
|---|---|
| [python] 박스 플롯 그리기 (0) | 2024.01.04 |